




I. PostgREST API pour PostgreSQL▲
PostgREST est un serveur Web autonome qui transforme votre base de données PostgreSQL directement en une API RESTful. Les contraintes structurelles et les autorisations dans la base de données déterminent les points de terminaison et les opérations de l'API. PostgREST permet d'exposer une base de données PostgreSQL sous forme d'API REST directement consommables par des applications mobiles, des portails Web ou bien des partenaires.
PostgREST sert une API entièrement RESTful à partir de tout type de base de données PostgreSQL existante. Selon l’équipe de développement, PostgREST fournit une API plus propre, plus conforme aux normes et plus rapide que celle que vous êtes susceptible d'écrire à partir de zéro. Elle estime que son utilisation est une alternative à la programmation manuelle CRUD. PostgREST est un middleware open source et les API exposées par PostgREST sont conformes à la spécification OpenAPI (anciennement connue sous le nom de spécification Swagger)." (Source : PostgREST : un serveur Web autonome qui transforme une base de données PostgreSQL, Bill Fassinou)
Cet article n'a pour objectif que de vous montrer comment je fais pour mettre en place PostgREST.
Vous trouverez plus d'informations sur la documentation officielle de PostgREST.
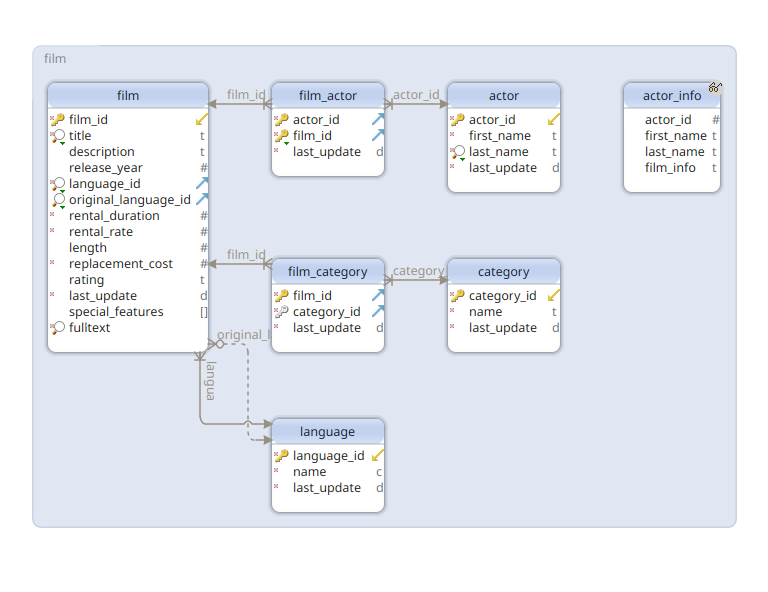
I-A. Schéma de base de données▲
Je pars du principe que vous disposez d'une instance PostgreSQL, pour enrichir les exemples, je vais installer la base de données SAKILA, que nous pouvons trouver sur GitHub.
Nous travaillerons sur quelques tables :
I-B. Installation▲
L'installation de PostgRESt se fait très facilement, il est possible d'utiliser un binaire pour :
- CentOS
- Ubuntu
- FreeBsd
- OSX
- Windows
Nous avons également la possibilité d'avoir accès aux sources et de disposer d’une image Docker.
C'est cette dernière que nous utiliserons pour l'installation de notre exemple.
Vous trouverez l'image officielle sur le docker hub.
Avant toute chose, nous allons définir un rôle qui peut faire des select dans la base de données. En effet, il n'est pas question d'utiliser le rôle postgres.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
-- création du rôle
create role anonymous nologin;
-- usage du schéma public
grant usage on schema public to anonymous;
-- donne le droit select aux tables qui nous intéressent
grant select on public.film to anonymous;
grant select on public.film_actor to anonymous;
grant select on public.actor to anonymous;
grant select on public.film_category to anonymous;
grant select on public.category to anonymous;
grant select on public.language to anonymous;
grant select on public.actor_info to anonymous;
Nous avons maintenant un rôle qui va pouvoir faire nos requêtes (select). Nous allons donc créer un rôle capable de se connecter à notre base de données.
2.
3.
4.
-- création du rôle authenticator
create role authenticator noinherit login password 'mysecretpassword';
-- accès des droits de authenticator sur anonymous
grant anonymous to authenticator;
On en profite pour ajouter quelques droits qui nous serviront plus tard pour insert/update et delete.
2.
3.
4.
5.
6.
7.
8.
9.
10.
-- insert dans la table film
GRANT INSERT ON TABLE public.film TO anonymous;
-- update dans la table film
GRANT UPDATE ON TABLE public.film TO anonymous;
-- delete dans la table film_actor
GRANT DELETE ON TABLE public.film_actor TO anonymous;
-- on ajoute également les droits à la séquence pour l'autoincrement
GRANT SELECT ON SEQUENCE public.film_film_id_seq TO anonymous;
GRANT UPDATE ON SEQUENCE public.film_film_id_seq TO anonymous;
GRANT USAGE ON SEQUENCE public.film_film_id_seq TO anonymous;
Maintenant que l'on peut se connecter à la base de données, nous allons lancer notre api via docker-compose.
Nous devons fournir un fichier de configuration avec notre instance PostgREST, voici les directives :
|
Name |
Type |
Default |
Required |
|---|---|---|---|
|
db-uri |
String |
Y |
|
|
db-schema |
String |
Y |
|
|
db-anon-role |
String |
Y |
|
|
db-pool |
Int |
10 |
|
|
db-pool-timeout |
Int |
10 |
|
|
db-extra-search-path |
String |
public |
|
|
server-host |
String |
!4 |
|
|
server-port |
Int |
3000 |
|
|
server-unix-socket |
String |
||
|
server-proxy-uri |
String |
||
|
jwt-secret |
String |
||
|
jwt-aud |
String |
||
|
secret-is-base64 |
Bool |
False |
|
|
max-rows |
Int |
? |
|
|
pre-request |
String |
||
|
app.settings.* |
String |
||
|
role-claim-key |
String |
.role |
|
|
raw-media-types |
String |
En Docker, toutes ces directives sont passées grâce à des variables d’environnement avec la nomenclature PGRST_DIRECTIVE_MAJUSCULE.
Trois directives sont obligatoires.
Voici un fichier yaml de base, dans lequel nous gardons nos informations sur une ip localhost.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
# docker-compose.yml
version: '3'
services:
server:
image: postgrest/postgrest
ports:
- "3000:3000"
environment:
PGRST_DB_URI: postgres://authenticator:mysecretpassword@localhost:5432/film
PGRST_DB_SCHEMA: public
PGRST_DB_ANON_ROLE: anonymous
network_mode: host
On crée notre instance Docker :
2.
3.
docker-compose up --no-start
Recreating postgrest_server_1 ...
Recreating postgrest_server_1 ... done
On lance notre instance :
2.
docker-compose start
Starting server ... done
Nous pouvons utiliser notre API.
I-C. Premiers pas▲
L'utilisation est très simple et en même temps, cela demande un peu de réflexion au départ.
La première requête que nous allons faire est d’accéder à notre API sur sa racine :
http://localhost:3000
Cette adresse retourne la documentation (OpenApi), qui pourra être traduite par Swagger (dont on parle plus bas), pour afficher une documentation automatique de notre API.
Bon à savoir : si vous enregistrez cette documentation dans un fichier.json, vous pourrez l'exporter dans un outil comme PostMan ou InsomniaRest ce qui créera automatiquement toutes les requêtes possibles.
Lançons notre première requête :
select * from film
cette requête au format API est très simple :
http://localhost:3000/film
Cela va nous retourner un json de l'ensemble de la table film, voici un exemple de sortie :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
[
{
"film_id": 1,
"title": "ACADEMY DINOSAUR",
"description": "A Epic Drama of a Feminist And a Mad Scientist who must Battle a Teacher in The Canadian Rockies",
"release_year": 2006,
"language_id": 1,
"original_language_id": null,
"rental_duration": 6,
"rental_rate": 0.99,
"length": 86,
"replacement_cost": 20.99,
"rating": "PG",
"last_update": "2006-02-15T05:03:42",
"special_features": [
"Deleted Scenes",
"Behind the Scenes"
],
"fulltext": "'academi':1 'battl':15 'canadian':20 'dinosaur':2 'drama':5 'epic':4 'feminist':8 'mad':11 'must':14 'rocki':21 'scientist':12 'teacher':17"
},
{
"film_id": 2,
"title": "ACE GOLDFINGER",
"description": "A Astounding Epistle of a Database Administrator And a Explorer who must Find a Car in Ancient China",
"release_year": 2006,
"language_id": 1,
"original_language_id": null,
"rental_duration": 3,
"rental_rate": 4.99,
"length": 48,
"replacement_cost": 12.99,
"rating": "G",
"last_update": "2006-02-15T05:03:42",
"special_features": [
"Trailers",
"Deleted Scenes"
],
"fulltext": "'ace':1 'administr':9 'ancient':19 'astound':4 'car':17 'china':20 'databas':8 'epistl':5 'explor':12 'find':15 'goldfing':2 'must':14"
}
]
Normalement, on devrait y trouver beaucoup plus de données, mais j'ai limité celles-ci à 2 en passant le paramètre « limit »
en réalité j'ai fait ceci :
select * from film limit 2
Ce qui en route API donne :
http://localhost:3000/film?limit=2
On voit donc ici qu'on utilise les routes http classiques, avec le passage en paramètres des données grâce aux caractères « ? » (point d'interrogation) et « & » (esperluette).
Nous voulons récupérer les films qui ont une longueur de 117, nous devons alors filtrer notre requête sur l’attribut « length » :
select * from film where length = 177
Notre route serait alors :
http://localhost:3000/film?length=eq.117
Si on décortique cette route, la particularité est la discrimination sur l'attribut length.
length=eq.117
le signe '=' attribue bien la valeur eq.117 , en effet , on doit bien dire à PotgreSQL ce qu'il doit faire et c'est le sigle eq qui spécifie que PostgreSQL doit faire dans un where une égalité. Autrement dit, la longueur doit être égale à 117.
Ce système a été choisi afin de pouvoir lancer la plupart de nos choix.
Voici un tableau reprenant l'ensemble des équivalences :
|
Abbreviation |
In PostgreSQL |
Meaning |
|---|---|---|
|
eq |
= |
equals |
|
gt |
> |
greater than |
|
gte |
>= |
greater than or equal |
|
lt |
< |
less than |
|
lte |
<= |
less than or equal |
|
neq |
<> or != |
not equal |
|
like |
LIKE |
LIKE operator (use * in place of %) |
|
ilike |
ILIKE |
ILIKE operator (use * in place of %) |
|
in |
IN |
one of a list of values, e.g. ?a=in.(1,2,3) – also supports commas in quoted strings like ?a=in.("hi,there","yes,you") |
|
is |
IS |
checking for exact equality (null,true,false) |
|
fts |
@@ |
Full-Text Search using to_tsquery |
|
plfts |
@@ |
Full-Text Search using plainto_tsquery |
|
phfts |
@@ |
Full-Text Search using phraseto_tsquery |
|
wfts |
@@ |
Full-Text Search using websearch_to_tsquery |
|
cs |
@> |
contains e.g. ?tags=cs.{example, new} |
|
cd |
<@ |
contained in e.g. ?values=cd.{1,2,3} |
|
ov |
&& |
overlap (have points in common), e.g. ?period=ov.[2017-01-01,2017-06-30] – also supports array types, use curly braces instead of square brackets e.g. :code: ?arr=ov.{1,3} |
|
sl |
<< |
strictly left of, e.g. ?range=sl.(1,10) |
|
sr |
>> |
strictly right of |
|
nxr |
&< |
does not extend to the right of, e.g. ?range=nxr.(1,10) |
|
nxl |
&> |
does not extend to the left of |
|
adj |
-|- |
is adjacent to, e.g. ?range=adj.(1,10) |
|
not |
NOT |
negates another operator, see below |
I-D. Qui fait quoi ?▲
Comment PostgREST fait-il pour retourner le résultat en Json ? C'est PostgreSQL lui-même qui s'en charge. En effet les lead developers sont partis du constat que le moteur PostgreSQL est le mieux à même de gérer toutes ses requêtes et de les restituer dans leur ensemble. Nous verrons plus loin qu'il utilise ce principe jusqu’à la sécurité des utilisateurs.
Donc si j'appelle la route :
http://localhost:3000/film?length=eq.117
Voici ce que PostgREST envoie à PostgreSQL :
2.
3.
4.
5.
6.
7.
8.
9.
WITH pg_source AS (
SELECT "public"."film".*
FROM "public"."film"
WHERE "public"."film"."length" = '117'::unknown
)
SELECT null AS total_result_set, pg_catalog.count(_postgrest_t) AS page_total,
array[]::text[] AS header,
coalesce(json_agg(_postgrest_t), '[]')::character varying AS body
FROM ( SELECT * FROM pg_source) _postgrest_t
Nous avons donc une CTE qui exécute notre requête et retourne le résultat sous forme de Json dans un attribut nommé body coalesce(json_agg(_postgrest_t), '[]')::character varying AS body
Ce mécanisme permet de faire l'abstraction d'une couche supplémentaire qu'un langage de programmation pourrait ajouter.
I-D-1. Complexifions nos requêtes▲
Si l'on ne veut qu'une partie de l'information, il faut pouvoir sélectionner ce que nous désirons. Nous allons donc travailler avec le jeu de données dont le film_id est 374.
Si l'on veut récupérer le jeu de données complet, nous aurions une route assez simple :
http://localhost:3000/film?film_id=eq.374
Une autre possibilité est de lui définir explicitement que nous voulons tout :
http://localhost:3000/film?select=*&film_id=eq.374
Cet élément select va nous permettre de définir les attributs que nous désirons :
http://localhost:3000/film?select=title,description,last_update&film_id=eq.374
Ce que PostgREST génère comme requête dans ce cas est :
2.
3.
4.
5.
6.
7.
8.
9.
10.
WITH pg_source AS (
SELECT "public"."film"."title", "public"."film"."description", "public"."film"."last_update"
FROM "public"."film"
WHERE "public"."film"."film_id" = '374'::unknown
)
SELECT null AS total_result_set, pg_catalog.count(_post WITH pg_source AS (SELECT "public"."film"."title", "public"."film"."description", "public"."film"."last_update" FROM "public"."film" WHERE "public"."film"."film_id" = '374'::unknown ) SELECT null AS total_result_set, pg_catalog.count(_postgrest_t) AS page_total, array[]::text[] AS header, coalesce(json_agg(_postgrest_t), '[]')::character varying AS body
FROM ( SELECT * FROM pg_source) _postgrest_tgrest_t) AS page_total,
array[]::text[] AS header,
coalesce(json_agg(_postgrest_t), '[]')::character varying AS body
FROM ( SELECT * FROM pg_source) _postgrest_t
On voit bien que cela sélectionne les attributs choisis.
Nous pouvons renommer nos attributs, il suffit de préfixer par : nouveauNom:atribut
http://localhost:3000/film?select=titre:title,chapeau:description,last_update&film_id=eq.374
2.
3.
4.
5.
6.
7.
[
{
"titre": "GRAFFITI LOVE",
"chapeau": "A Unbelieveable Epistle of a Sumo Wrestler And a Hunter who must Build a Composer in Berlin",
"last_update": "2006-02-15T05:03:42"
}
]
Nous pouvons également caster nos valeurs, de la même façon que PostgreSQL caste :
Sans cast :
http://localhost:3000/film?select=rental_rate&film_id=eq.374
2.
3.
4.
5.
[
{
"rental_rate": 0.99
}
]
Avec cast :
http://localhost:3000/film?select=rental_rate::text&film_id=eq.374
2.
3.
4.
5.
[
{
"rental_rate": "0.99"
}
]
Si je veux rechercher le titre 'ANGELS LIFE', l'idéal sera d'utiliser le like en ajoutant de en lieu et place des %
http://localhost:3000/film?select=*&title=like.*ANGELS LIFE*
Mais nous pourrions aussi remplacer l'espace par comme la convention html nous le permet et utiliser une égalité au lieu du like :
http://localhost:3000/film?select=*&title=eq.ANGELS LIFE
Mais cela est beaucoup plus laborieux.
Nous pouvons bien sûr filtrer le tout sur plusieurs attributs :
http://localhost:3000/film?select=titre:title&length=eq.117&rental_duration=eq.3
2.
3.
4.
5.
6.
7.
8.
[
{
"titre": "GRAFFITI LOVE"
},
{
"titre": "MAGIC MALLRATS"
}
]
Je pense que nous avons bien compris le principe.
I-D-2. Jointure de tables (embedded)▲
PostgREST se base sur les contraintes de foreign key définies dans la base de données pour faire les jointures naturelles des requêtes, ces jointures se font donc sur les clefs définies (qu'elles soient primaires (primary key) ou non).
La jointure s'organise dans le select en prenant en plus des attributs, le nom de la table à joindre. Exemple entre un film et sa langue :
http://localhost:3000/film?select=*,language(*)&limit=2
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
[
{
"film_id": 1,
"title": "ACADEMY DINOSAUR",
"description": "A Epic Drama of a Feminist And a Mad Scientist who must Battle a Teacher in The Canadian Rockies",
"release_year": 2006,
"language_id": 1,
"original_language_id": null,
"rental_duration": 6,
"rental_rate": 0.99,
"length": 86,
"replacement_cost": 20.99,
"rating": "PG",
"last_update": "2006-02-15T05:03:42",
"special_features": [
"Deleted Scenes",
"Behind the Scenes"
],
"fulltext": "'academi':1 'battl':15 'canadian':20 'dinosaur':2 'drama':5 'epic':4 'feminist':8 'mad':11 'must':14 'rocki':21 'scientist':12 'teacher':17",
"language": {
"language_id": 1,
"name": "English ",
"last_update": "2006-02-15T05:02:19"
}
},
{
"film_id": 2,
"title": "ACE GOLDFINGER",
"description": "A Astounding Epistle of a Database Administrator And a Explorer who must Find a Car in Ancient China",
"release_year": 2006,
"language_id": 1,
"original_language_id": null,
"rental_duration": 3,
"rental_rate": 4.99,
"length": 48,
"replacement_cost": 12.99,
"rating": "G",
"last_update": "2006-02-15T05:03:42",
"special_features": [
"Trailers",
"Deleted Scenes"
],
"fulltext": "'ace':1 'administr':9 'ancient':19 'astound':4 'car':17 'china':20 'databas':8 'epistl':5 'explor':12 'find':15 'goldfing':2 'must':14",
"language": {
"language_id": 1,
"name": "English ",
"last_update": "2006-02-15T05:02:19"
}
}
]
Nous voyons dans le résultat que nous avons les données de la table « language », pour récupérer les attributs spécifiques de la table jointe, il faut les définir dans le nom de la table entre parenthèses, comme ici language(name)
http://localhost:3000/film?select=*,language(name)&limit=2
Cette requête dans PostgreSQL, donne ceci :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
WITH pg_source AS (
SELECT "public"."film".*, row_to_json("language_language".*) AS "language"
FROM "public"."film"
LEFT JOIN LATERAL(
SELECT "public"."language"."name" FROM "public"."language"
WHERE "public"."language"."language_id" = "public"."film"."language_id" ) AS "language_language" ON true
LIMIT 2 OFFSET 0
)
SELECT null AS total_result_set, pg_catalog.count(_postgrest_t) AS page_total,
array[]::text[] AS header,
coalesce(json_agg(_postgrest_t), '[]')::character varying AS body
FROM ( SELECT * FROM pg_source) _postgrest_t
Nous remarquons deux choses importantes, c'est que PostgREST utilise la fonction row_to_json(), pour faire l'embed de la table jointe, ce qui permet d'avoir également du Json.
La deuxième remarque est que la jointure est une jointure latérale de gauche, un LEFT JOIN LATERAL. Il faut en tenir compte, car pour le moment le INNER JOIN n'est pas possible.
Si on modifie quelque peu le contenu de la base de données :
update film set language_id = 2 where film_id = 2;
Afin d'avoir un film en italien et parce que je veux discriminer sur la table language, alors un left join retournera tout, même s'il ne trouve pas de données auquel cas, il restituera les attributs correspondants à « NULL ».
http://localhost:3000/film?select=*,language(name)&language.name=like.*Italian*
Donc ici, on fait une jointure dont l'attribut name de la table language est like '%Italian%'
Voici une partie du résultat :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
{
"film_id": 1000,
"title": "ZORRO ARK",
"description": "A Intrepid Panorama of a Mad Scientist And a Boy who must Redeem a Boy in A Monastery",
"release_year": 2006,
"language_id": 1,
"original_language_id": null,
"rental_duration": 3,
"rental_rate": 4.99,
"length": 50,
"replacement_cost": 18.99,
"rating": "NC-17",
"last_update": "2006-02-15T05:03:42",
"special_features": [
"Trailers",
"Commentaries",
"Behind the Scenes"
],
"fulltext": "'ark':2 'boy':12,17 'intrepid':4 'mad':8 'monasteri':20 'must':14 'panorama':5 'redeem':15 'scientist':9 'zorro':1",
"language": null
},
{
"film_id": 2,
"title": "ACE GOLDFINGER",
"description": "A Astounding Epistle of a Database Administrator And a Explorer who must Find a Car in Ancient China",
"release_year": 2006,
"language_id": 2,
"original_language_id": null,
"rental_duration": 3,
"rental_rate": 4.99,
"length": 48,
"replacement_cost": 12.99,
"rating": "G",
"last_update": "2019-12-11T14:26:49.203836",
"special_features": [
"Trailers",
"Deleted Scenes"
],
"fulltext": "'ace':1 'administr':9 'ancient':19 'astound':4 'car':17 'china':20 'databas':8 'epistl':5 'explor':12 'find':15 'goldfing':2 'must':14",
"language": {
"name": "Italian "
}
}
]
On voit que le embed de language retourne des name null et les name Italian.
Il faudra alors penser à inverser la requête que l'on recherche à faire :
http://localhost:3000/language?select=name,film(*)&name=like.*Italian*
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
[
{
"name": "Italian ",
"film": [
{
"film_id": 2,
"title": "ACE GOLDFINGER",
"description": "A Astounding Epistle of a Database Administrator And a Explorer who must Find a Car in Ancient China",
"release_year": 2006,
"language_id": 2,
"original_language_id": null,
"rental_duration": 3,
"rental_rate": 4.99,
"length": 48,
"replacement_cost": 12.99,
"rating": "G",
"last_update": "2019-12-11T14:29:53.488058",
"special_features": [
"Trailers",
"Deleted Scenes"
],
"fulltext": "'ace':1 'administr':9 'ancient':19 'astound':4 'car':17 'china':20 'databas':8 'epistl':5 'explor':12 'find':15 'goldfing':2 'must':14"
}
]
}
]
Du coup, ici, c'est film qui est embed de language.
I-D-3. Multi jointure de tables▲
Il est tout à fait possible de joindre plusieurs tables si le schéma le permet ; par exemple, film, language, film_actor et cela juste en ajoutant les tables à joindre :
http://localhost:3000/film?select=*,language(*),film_actor(*)&limit=2
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
71.
72.
73.
74.
75.
76.
77.
78.
79.
80.
81.
82.
83.
84.
85.
86.
87.
88.
89.
90.
91.
92.
93.
94.
95.
96.
97.
98.
99.
100.
101.
102.
103.
104.
105.
106.
107.
108.
109.
110.
111.
112.
113.
114.
115.
116.
117.
118.
119.
120.
121.
122.
123.
124.
125.
126.
127.
128.
129.
[
{
"film_id": 1,
"title": "ACADEMY DINOSAUR",
"description": "A Epic Drama of a Feminist And a Mad Scientist who must Battle a Teacher in The Canadian Rockies",
"release_year": 2006,
"language_id": 1,
"original_language_id": null,
"rental_duration": 6,
"rental_rate": 0.99,
"length": 86,
"replacement_cost": 20.99,
"rating": "PG",
"last_update": "2006-02-15T05:03:42",
"special_features": [
"Deleted Scenes",
"Behind the Scenes"
],
"fulltext": "'academi':1 'battl':15 'canadian':20 'dinosaur':2 'drama':5 'epic':4 'feminist':8 'mad':11 'must':14 'rocki':21 'scientist':12 'teacher':17",
"language": {
"language_id": 1,
"name": "English ",
"last_update": "2006-02-15T05:02:19"
},
"film_actor": [
{
"actor_id": 1,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 10,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 20,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 30,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 40,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 53,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 108,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 162,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 188,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 198,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
}
]
},
{
"film_id": 3,
"title": "ADAPTATION HOLES",
"description": "A Astounding Reflection of a Lumberjack And a Car who must Sink a Lumberjack in A Baloon Factory",
"release_year": 2006,
"language_id": 1,
"original_language_id": null,
"rental_duration": 7,
"rental_rate": 2.99,
"length": 50,
"replacement_cost": 18.99,
"rating": "NC-17",
"last_update": "2006-02-15T05:03:42",
"special_features": [
"Trailers",
"Deleted Scenes"
],
"fulltext": "'adapt':1 'astound':4 'baloon':19 'car':11 'factori':20 'hole':2 'lumberjack':8,16 'must':13 'reflect':5 'sink':14",
"language": {
"language_id": 1,
"name": "English ",
"last_update": "2006-02-15T05:02:19"
},
"film_actor": [
{
"actor_id": 2,
"film_id": 3,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 19,
"film_id": 3,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 24,
"film_id": 3,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 64,
"film_id": 3,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 123,
"film_id": 3,
"last_update": "2006-02-15T05:05:03"
}
]
}
]
On voit ici que film_actor est joint dans le résultat.
Si on veut les acteurs des films, on appelle les tables concernées :
http://localhost:3000/film?select=*,film_actor(*),actor(*)&limit=1
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
71.
72.
73.
74.
75.
76.
77.
78.
79.
80.
81.
82.
83.
84.
85.
86.
87.
88.
89.
90.
91.
92.
93.
94.
95.
96.
97.
98.
99.
100.
101.
102.
103.
104.
105.
106.
107.
108.
109.
110.
111.
112.
113.
114.
115.
116.
117.
118.
119.
120.
121.
122.
123.
124.
125.
126.
127.
128.
129.
130.
131.
132.
133.
134.
135.
[
{
"film_id": 1,
"title": "ACADEMY DINOSAUR",
"description": "A Epic Drama of a Feminist And a Mad Scientist who must Battle a Teacher in The Canadian Rockies",
"release_year": 2006,
"language_id": 1,
"original_language_id": null,
"rental_duration": 6,
"rental_rate": 0.99,
"length": 86,
"replacement_cost": 20.99,
"rating": "PG",
"last_update": "2006-02-15T05:03:42",
"special_features": [
"Deleted Scenes",
"Behind the Scenes"
],
"fulltext": "'academi':1 'battl':15 'canadian':20 'dinosaur':2 'drama':5 'epic':4 'feminist':8 'mad':11 'must':14 'rocki':21 'scientist':12 'teacher':17",
"film_actor": [
{
"actor_id": 1,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 10,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 20,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 30,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 40,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 53,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 108,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 162,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 188,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
},
{
"actor_id": 198,
"film_id": 1,
"last_update": "2006-02-15T05:05:03"
}
],
"actor": [
{
"actor_id": 1,
"first_name": "PENELOPE",
"last_name": "GUINESS",
"last_update": "2006-02-15T04:34:33"
},
{
"actor_id": 10,
"first_name": "CHRISTIAN",
"last_name": "GABLE",
"last_update": "2006-02-15T04:34:33"
},
{
"actor_id": 20,
"first_name": "LUCILLE",
"last_name": "TRACY",
"last_update": "2006-02-15T04:34:33"
},
{
"actor_id": 30,
"first_name": "SANDRA",
"last_name": "PECK",
"last_update": "2006-02-15T04:34:33"
},
{
"actor_id": 40,
"first_name": "JOHNNY",
"last_name": "CAGE",
"last_update": "2006-02-15T04:34:33"
},
{
"actor_id": 53,
"first_name": "MENA",
"last_name": "TEMPLE",
"last_update": "2006-02-15T04:34:33"
},
{
"actor_id": 108,
"first_name": "WARREN",
"last_name": "NOLTE",
"last_update": "2006-02-15T04:34:33"
},
{
"actor_id": 162,
"first_name": "OPRAH",
"last_name": "KILMER",
"last_update": "2006-02-15T04:34:33"
},
{
"actor_id": 188,
"first_name": "ROCK",
"last_name": "DUKAKIS",
"last_update": "2006-02-15T04:34:33"
},
{
"actor_id": 198,
"first_name": "MARY",
"last_name": "KEITEL",
"last_update": "2006-02-15T04:34:33"
}
]
}
]
Dans ce cas, nous devrons alors, grâce à un langage de programmation, refaire les jointures entre film_actor et actor.
Il est aussi possible de joindre la table actor à la jointure de la table film_actor :
http://localhost:3000/film?select=*,film_actor(*,actor(*))&limit=1
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
71.
72.
73.
74.
75.
76.
77.
78.
79.
80.
81.
82.
83.
84.
85.
86.
87.
88.
89.
90.
91.
92.
93.
94.
95.
96.
97.
98.
99.
100.
101.
102.
103.
104.
105.
106.
107.
108.
109.
110.
111.
112.
113.
114.
115.
116.
117.
118.
119.
120.
121.
122.
123.
124.
125.
126.
127.
128.
129.
130.
131.
132.
133.
[
{
"film_id": 1,
"title": "ACADEMY DINOSAUR",
"description": "A Epic Drama of a Feminist And a Mad Scientist who must Battle a Teacher in The Canadian Rockies",
"release_year": 2006,
"language_id": 1,
"original_language_id": null,
"rental_duration": 6,
"rental_rate": 0.99,
"length": 86,
"replacement_cost": 20.99,
"rating": "PG",
"last_update": "2006-02-15T05:03:42",
"special_features": [
"Deleted Scenes",
"Behind the Scenes"
],
"fulltext": "'academi':1 'battl':15 'canadian':20 'dinosaur':2 'drama':5 'epic':4 'feminist':8 'mad':11 'must':14 'rocki':21 'scientist':12 'teacher':17",
"film_actor": [
{
"actor_id": 1,
"film_id": 1,
"last_update": "2006-02-15T05:05:03",
"actor": {
"actor_id": 1,
"first_name": "PENELOPE",
"last_name": "GUINESS",
"last_update": "2006-02-15T04:34:33"
}
},
{
"actor_id": 10,
"film_id": 1,
"last_update": "2006-02-15T05:05:03",
"actor": {
"actor_id": 10,
"first_name": "CHRISTIAN",
"last_name": "GABLE",
"last_update": "2006-02-15T04:34:33"
}
},
{
"actor_id": 20,
"film_id": 1,
"last_update": "2006-02-15T05:05:03",
"actor": {
"actor_id": 20,
"first_name": "LUCILLE",
"last_name": "TRACY",
"last_update": "2006-02-15T04:34:33"
}
},
{
"actor_id": 30,
"film_id": 1,
"last_update": "2006-02-15T05:05:03",
"actor": {
"actor_id": 30,
"first_name": "SANDRA",
"last_name": "PECK",
"last_update": "2006-02-15T04:34:33"
}
},
{
"actor_id": 40,
"film_id": 1,
"last_update": "2006-02-15T05:05:03",
"actor": {
"actor_id": 40,
"first_name": "JOHNNY",
"last_name": "CAGE",
"last_update": "2006-02-15T04:34:33"
}
},
{
"actor_id": 53,
"film_id": 1,
"last_update": "2006-02-15T05:05:03",
"actor": {
"actor_id": 53,
"first_name": "MENA",
"last_name": "TEMPLE",
"last_update": "2006-02-15T04:34:33"
}
},
{
"actor_id": 108,
"film_id": 1,
"last_update": "2006-02-15T05:05:03",
"actor": {
"actor_id": 108,
"first_name": "WARREN",
"last_name": "NOLTE",
"last_update": "2006-02-15T04:34:33"
}
},
{
"actor_id": 162,
"film_id": 1,
"last_update": "2006-02-15T05:05:03",
"actor": {
"actor_id": 162,
"first_name": "OPRAH",
"last_name": "KILMER",
"last_update": "2006-02-15T04:34:33"
}
},
{
"actor_id": 188,
"film_id": 1,
"last_update": "2006-02-15T05:05:03",
"actor": {
"actor_id": 188,
"first_name": "ROCK",
"last_name": "DUKAKIS",
"last_update": "2006-02-15T04:34:33"
}
},
{
"actor_id": 198,
"film_id": 1,
"last_update": "2006-02-15T05:05:03",
"actor": {
"actor_id": 198,
"first_name": "MARY",
"last_name": "KEITEL",
"last_update": "2006-02-15T04:34:33"
}
}
]
}
]
On comprend aisément que l'outil est puissant et que tout n'est question que d'imbrications.
I-D-4. Pagination▲
Il est tout à fait possible de retourner un jeu de résultats ordonné :
http://localhost:3000/film?order=language_id.desc
Ou de ne prendre qu'un offset pour paginer :
http://localhost:3000/film?order=language_id.desc&offset=30
Cette commande va prendre tout sauf les trente premiers résultats.
Une autre façon de faire est de spécifier dans les en-têtes l’intervalle (« range ») que nous voulons recevoir.
2.
3.
4.
5.
> GET /film?order=language_id.desc&offset=30 HTTP/1.1
> Host: localhost:3000
> User-Agent: insomnia/7.0.5
> Range: 0-50
> Accept: */*
Ici, nous aurons donc les 50 premiers résultats, pour les 50 suivants :
2.
3.
4.
5.
> GET /film?order=language_id.desc&offset=30 HTTP/1.1
> Host: localhost:3000
> User-Agent: insomnia/7.0.5
> Range: 51-100
> Accept: */*
Si, en plus, on veut le total de lignes possibles (count()), il faut aussi le spécifier dans l'en-tête avec la condition Prefer qui a pour valeur count=exact :
2.
3.
4.
5.
6.
> GET /film?order=language_id.desc&offset=30 HTTP/1.1
> Host: localhost:3000
> User-Agent: insomnia/7.0.5
> Range: 51-100
> Prefer: count=exact
> Accept: */*
Qui aura comme retour dans les headers :
2.
3.
4.
5.
6.
Transfer-Encoding: chunked
Date: Wed, 11 Dec 2019 14:38:50 GMT
Server: postgrest/6.0.2 (713b214)
Content-Type: application/json; charset=utf-8
Content-Range: 51-100/1000
Content-Location: /film?offset=30&order=language_id.desc
Avec cette information Content-Range: 51-100/1000, nous pourrons paginer.
I-E. Insertion▲
Une insertion est un post avec en paramètre un json reprenant les données à insérer.
Cela se fait au moyen d’un outil de type insomnia ou en langage de programmation.
On crée la route en POST et on passe un json :
2.
3.
4.
5.
6.
7.
{
"title": "Henallux",
"description": "G² fait un tuto pour ses collègues",
"release_year": 2006,
"language_id": 5,
"fulltext": "'abandon':20 'amus':21 'bang':1 'cat':11 'drama':5 'epic':4 'face':14 'kwai':2 'madman':8 'must':13 'park':22 'shark':17"
}
Si tout se passe bien, on récupère une réponse 201, avec en prime la route qui nous permet de vérifier :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
> POST /film HTTP/1.1
> Host: localhost:3000
> User-Agent: insomnia/7.0.5
> Content-Type: application/json
> Accept: */*
> Content-Length: 278
{
"title": "Henallux",
"description": "G² fait un tuto pour ses collègues",
"release_year": 2006,
"language_id": 5,
"fulltext": "'abandon':20 'amus':21 'bang':1 'cat':11 'drama':5 'epic':4 'face':14 'kwai':2 'madman':8 'must':13 'park':22 'shark':17"
}
* upload completely sent off: 278 out of 278 bytes
* Mark bundle as not supporting multiuse
< HTTP/1.1 201 Created
< Transfer-Encoding: chunked
< Date: Wed, 11 Dec 2019 15:02:56 GMT
< Server: postgrest/6.0.2 (713b214)
< Location: /film?film_id=eq.1001
< Content-Range: */
I-F. Delete▲
Pour le delete, on crée une route avec le verbe delete et les paramètres de discrimination.
Pour supprimer une ligne dans la table film_actor :
http://localhost:3000/film_actor?actor_id=eq.1&film_id=eq.23
Le retour :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
> DELETE /film_actor?actor_id=eq.1&film_id=eq.23 HTTP/1.1
> Host: localhost:3000
> User-Agent: insomnia/7.0.5
> Accept: */*
* Mark bundle as not supporting multiuse
< HTTP/1.1 204 No Content
< Date: Thu, 12 Dec 2019 08:29:54 GMT
< Server: postgrest/6.0.2 (713b214)
< Content-Range: */*
I-G. Update▲
Pour l'update c'est aussi facile, on discrimine une route et on envoie un json avec les attributs à modifier.
http://localhost:3000/film?film_id=eq.1001
2.
3.
4.
5.
{
"title": "Henallux the retour :) ",
"release_year": 2019
}
I-H. REST Classique et Https▲
Nous sommes plus souvent habitués à avoir des routes du genre :
http://localhost:3000/film/4
Pour récupérer l'ensemble des informations de la table film qui a pour id 4, ce n'est pas la solution prise par PostgREST, qui veut être proche d'une nomenclature du genre de GraphQL.
Néanmoins, cela peut se mettre en place facilement avec un proxy de type Nginx
2.
3.
4.
5.
6.
7.
8.
9.
# support /endpoint/:id url style
location ~ ^/([a-z_]+)/([0-9]+) {
# make the response singular
proxy_set_header Accept 'application/vnd.pgrst.object+json';
proxy_pass http://localhost:3000/fiml?film_id=eq.$1;
}
De même, je vous renvoie sur la doc de votre proxy pour gérer la sécurisation (https) de vos requêtes.
II. Swagger▲
PostgREST est conforme à la spécification OpenAPI , c'est d'ailleurs cette spécification qui est envoyée en appelant l'API à sa racine.
Il est donc possible d'autodocumenter ses routes avec une image docker de Swagger.
Dans le fichier docker-compose, on ajoute les lignes suivantes :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
# docker-compose.yml
version: '3'
services:
server:
image: postgrest/postgrest
ports:
- "3000:3000"
environment:
PGRST_DB_URI: postgres://authenticator:mysecretpassword@localhost:5432/film
PGRST_DB_SCHEMA: public
PGRST_DB_ANON_ROLE: anonymous
network_mode: host
swagger:
image: swaggerapi/swagger-ui
ports:
- "8181:8080"
expose:
- "8181"
environment:
API_URL: http://localhost:3000/
Et sur le port 8181 en localhost, on obtient une documentation de nos routes.
![[ALT-PASTOUCHE]](./images/swagger.png)
III. Authentification JWT▲
Il existe plusieurs façons de sécuriser son API, mon choix c'est porté sur le Json Web Token qui est un standard lié à la RFC 7519, grâce au site jwt.io, on peut voir qu'il existe une extension pour PostgreSQL qui est facile à mettre en place.
Je vais décrire ici le processus que j'ai mis en place pour sécuriser mon API.
Mon moteur de base de données PostgreSQL tourne sur une Ubuntu Server
La procédure n'est pas compliquée, mais un peu longue.
III-A. Principe de base▲
Ce que nous allons mettre en place, c'est un système d'utilisateurs qui se substitueront à un rôle.
Un rôle avec des droits spécifiques sera créé dans PostgreSQL. Dans une table, nous créerons des utilisateurs qui prendront le statut du rôle créé et pourront lancer des requêtes.
De nouveau, nous déléguons à PostgreSQL le soin de gérer ses droits (grant), cela va permettre de créer des rôles avec une granularité limitée par les possibilités de PostgreSQL, autant dire peu de contraintes.
III-A-1. Installation extension jwt PostgreSQL▲
On commence par installer les outils de développement PostgreSQL. Dans mon cas, c’est en version 11.
sudo apt-get install postgresql-server-dev-11
Ensuite, on clone le projet pgjwt (n'oubliez pas de le forker, on ne sait jamais). Et on rentre dans le répertoire :
git clone https://github.com/michelp/pgjwt.git && cd pgjwt
On installe l'extension dans PostgreSQL :
sudo make install
Normalement la sortie donne quelque chose comme :
2.
3.
4.
/bin/mkdir -p '/usr/share/postgresql/11/extension'
/bin/mkdir -p '/usr/share/postgresql/11/extension'
/usr/bin/install -c -m 644 .//pgjwt.control '/usr/share/postgresql/11/extension/'
/usr/bin/install -c -m 644 .//pgjwt--0.1.0.sql '/usr/share/postgresql/11/extension/'
Voilà pour la partie serveur ; c'est fini.
III-A-2. Activation des extensions dans PostgreSQL▲
Nous avons besoin de deux extensions pgcrypto (pour crypter) et pgjwt que nous venons de compiler.
2.
create extension pgcrypto;
create extension pgjwt;
III-A-3. Mise en place des processus JWT▲
Jwt étant basé sur une clef secrète, on va la stocker dans notre DB (32 caractères, c'est bien !)
ALTER DATABASE film SET "public.jwt_secret" TO 'mysuperkeysecretmysuperkeysecret';
Création d'un schéma pour la gestion de l'authentification :
create schema if not exists basic_auth;
Création de la table qui va gérer nos utilisateurs (différents des rôles, donc) :
2.
3.
4.
5.
6.
create table if not exists
basic_auth.users (
pseudo text primary key check ( length(pseudo) < 50),
pass text not null check (length(pass) < 512),
role name not null check (length(role) < 512)
);
Il faut créer maintenant une série de fonctions et procédures qui vont nous permettre de tout faire fonctionner.
Création de la fonction qui va vérifier que le rôle existe :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
create or replace function
basic_auth.check_role_exists() returns trigger as $$
begin
if not exists (select 1 from pg_roles as r where r.rolname = new.role) then
raise foreign_key_violation using message =
'unknown database role: ' || new.role;
return null;
end if;
return new;
end
$$ language plpgsql;
Création de la procédure qui, après un insert ou update de la table users, va lancer la fonction basic_auth.check_role_exists() :
2.
3.
4.
5.
drop trigger if exists ensure_user_role_exists on basic_auth.users;
create constraint trigger ensure_user_role_exists
after insert or update on basic_auth.users
for each row
execute procedure basic_auth.check_role_exists();
Création de la fonction qui va crypter notre mot de passe en bf, md5, xdes, des. Je vous renvoie à la doc de pgcrypto pour plus de renseignements : https://www.postgresql.org/docs/11/pgcrypto.html
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
create or replace function
basic_auth.encrypt_pass() returns trigger as $$
begin
if tg_op = 'INSERT' or new.pass <> old.pass then
new.pass = crypt(new.pass, gen_salt('bf'));
end if;
return new;
end
$$ language plpgsql;
-- triger sur insert ou update
drop trigger if exists encrypt_pass on basic_auth.users;
create trigger encrypt_pass
before insert or update on basic_auth.users
for each row
execute procedure basic_auth.encrypt_pass();
Création de la fonction qui va substituer le rôle anonymous de base, à celui défini par la table users
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
create or replace function
basic_auth.user_role(pseudo text, pass text) returns name
language plpgsql
as $$
begin
return (
select role from basic_auth.users
where users.pseudo = user_role.pseudo
and users.pass = crypt(user_role.pass, users.pass)
);
end;
$$;
Création d’un type token :
2.
3.
CREATE TYPE basic_auth.jwt_token AS (
token text
);
Création de la fonction login, à mettre dans votre schéma courant (ici public) :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
CREATE OR REPLACE FUNCTION public.login(
pseudo text,
pass text)
RETURNS basic_auth.jwt_token
LANGUAGE 'plpgsql'
COST 100
VOLATILE SECURITY DEFINER
AS $BODY$
declare
_role name;
result basic_auth.jwt_token;
begin
-- check email and password
select basic_auth.user_role(pseudo, pass) into _role;
if _role is null then
raise invalid_password using message = 'invalid user or password';
end if;
select sign(
row_to_json(r), current_setting('public.jwt_secret')
) as token
from (
select _role as role, login.pseudo as pseudo,
extract(epoch from now())::integer + 60*60 as exp
) r
into result;
return result;
end;
$BODY$;
Attribution des droits qui vont bien :
2.
3.
4.
5.
6.
7.
8.
ALTER FUNCTION brain.login(text, text)
OWNER TO postgres;
GRANT EXECUTE ON FUNCTION brain.login(text, text) TO postgres;
GRANT EXECUTE ON FUNCTION brain.login(text, text) TO PUBLIC;
GRANT EXECUTE ON FUNCTION brain.login(text, text) TO anonymous;
Si vous avez suivi l'article depuis le début, vous comprendrez qu’il faut enlever des droits au rôle anonymous pour qu'il ne puisse que faire usage du schéma public, rien d'autre :
2.
3.
REVOKE ALL ON table language,category,actor_info,film_category,actor,film_actor,film FROM anonymous;
GRANT anonymous to authenticator;
GRANT USAGE ON SCHEMA public TO anonymous;
Je vous renvoie au début de l'article pour la gestion de authenticator et anonymous.
Création d’un rôle qui pourra avoir les droits select sur les tables film, film_actor et actor
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
CREATE ROLE "readall" WITH
NOLOGIN
NOSUPERUSER
NOCREATEDB
NOCREATEROLE
INHERIT
NOREPLICATION
CONNECTION LIMIT -1;
-- on donne la possibilité à anonymous de changer de rôle
GRANT readall TO anonymous;
-- on donne le droit usage au schéma public
GRANT USAGE ON SCHEMA public TO readall;
-- on donne les droits aux tables
GRANT SELECT ON TABLE public.actor TO "readall";
GRANT SELECT ON TABLE public.film TO "readall";
GRANT SELECT ON TABLE public.film_actor TO "readall";
Création d’un user qui va créer un token et prendre le rôle readall:
INSERT INTO basic_auth.users (pseudo,pass,role) VALUES ('jhon','bonjour','readall');
Qui avec les fonctions de pgcrypto donnera ceci :
2.
"pseudo","pass","role"
"jhon","$2a$06$i5OZQuo1A0Vg4QOf1Y4sZeARndLOWLtF6v0UFCZfwFy30xW3XSdXC","readall"
À partir de maintenant, si on ne possède pas de token, nous n'avons plus accès à nos données :
2.
3.
4.
5.
6.
{
"hint": null,
"details": null,
"code": "42501",
"message": "permission denied for table film"
}
III-A-4. Login▲
Nous devons maintenant nous connecter pour disposer d'un token.
Les routes, permettant d'avoir accès aux fonctions, doivent être précédées de rpc.
Donc pour se connecter, avec une route en POST :
http://localhost:3000/rpc/login
Et le json qui va bien :
2.
3.
4.
{
"pseudo":"jhon",
"pass":"bonjour"
}
On va donc prendre le rôle de readall et cela va nous retourner un token de type bearer :
2.
3.
4.
5.
[
{
"token": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJyb2xlIjoicmVhZGFsbCIsInBzZXVkbyI6Impob24iLCJleHAiOjE1NzYxNjEwNzZ9.cV6gdduj0xpaT3fg4zqtswNDdxGZpr-06kq2aDqnk8A"
}
]
Nous aurons besoin maintenant d'une Authorisation de type Bearer pour faire nos requêtes et être ainsi sécurisés.
Donc, pour une requête sur la table film, un get avec le token :
2.
3.
4.
5.
6.
> GET /film HTTP/1.1
> Host: localhost:3000
> User-Agent: insomnia/7.0.5
> Prefer: count=exact
> Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJyb2xlIjoicmVhZGFsbCIsInBzZXVkbyI6Impob24iLCJleHAiOjE1NzYxNjEwNzZ9.cV6gdduj0xpaT3fg4zqtswNDdxGZpr-06kq2aDqnk8A
> Accept: */*
IV. Http-Client Symfony▲
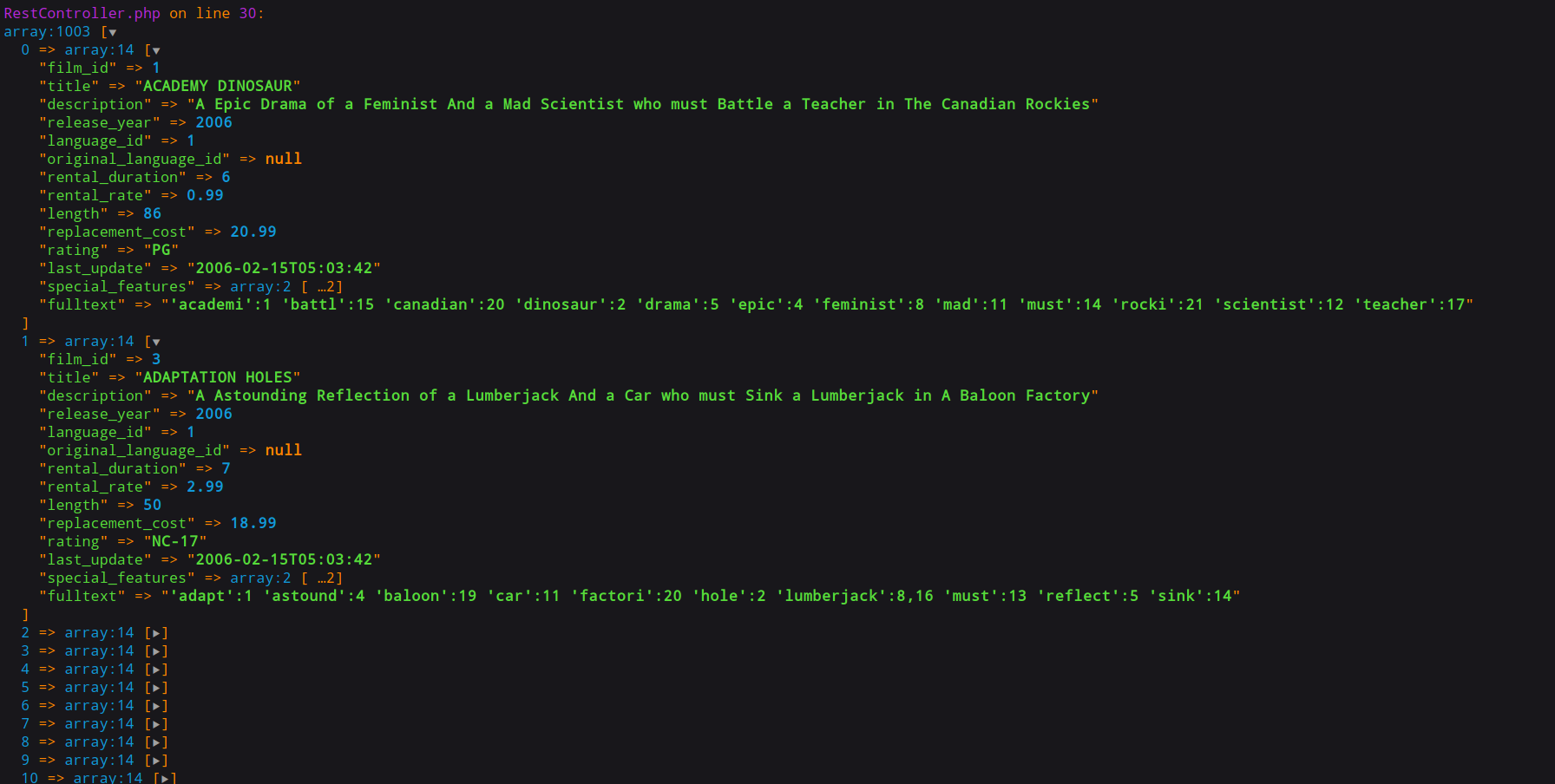
Je travaille essentiellement en PHP, voici donc comment, dans mon langage de prédilection, je fais pour une requête GET :
J'installe d'abord le http-client dans mon projet Symfony, Laravel, Yii, ou autre…
composer require symfony/http-client
J’exécute ensuite le code suivant :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
// j'instancie le client
$client = HttpClient::create();
// je récupère le token
$token = $client->request('POST', 'http://localhost:3000/rpc/login', [
'body' => ["pseudo" => "jhon", "pass" => "bonjour"]
]);
// je crée un ensemble d'options, avec le token
$options = [
'headers' => [
'Prefer' => 'count=exact',
'Authorization' => 'Bearer ' . $token->toArray()[0]['token']]
];
// j'appelle mon API, avec le token en options
$response = $client->request('GET', 'http://localhost:3000/film', $options);
// j'affiche le résultat sous forme de tableau
dd($response->toArray());
Résultat
V. Conclusion▲
PostgREST offre une API qui utilise toute la puissance de PostgreSQL et cela de façon presque naturelle.
Si les routes se complexifient, il faut alors se retourner vers les vues, qui étendront aisément toutes nos requêtes.
Le projet est en développement actif et les membres sont assez réactifs à nos demandes.
Ce projet remplacera facilement tout CRUD inutile à développer, en plus d'offrir à vos utilisateurs la possibilité de recevoir des données non limitées par des routes, qui contraignent la sortie.
VI. Remerciments▲
Que soient remerciés ici tous ceux qui m'ont apporté une aide précieuse à la confection de cet article, je pense à Grazouilli et Escartefigue (pour les fôtes) ainsi que Claude Leloup (pour le XML).